

Introduction
Neural Networks are fascinating computational models extracted from the idea of the functioning of the human brain. These models are often used in today's Artificial Intelligence due to their ability to learn almost any kind of data, no matter whether it is simple or incredibly complex.
The concept behind Neural Networks is really simple and straightforward, consisting of calculating the dot product of weights and inputs, applying activation, and forwarding the result to the next neuron for further processing.
However, in order for a Neural Network to have an idea of the given data, it must undergo a process called learning or training. This is similar to the way humans acquire knowledge. Learning is the most crucial step for all kinds of machine learning algorithms to understand data and make predictions in a real-world scenario.
For Neural Networks to learn, we use an algorithm called Backpropagation. Backpropagation is the core algorithm behind the learning of Neural Networks, specifically Feed-Forward Artificial Neural Networks, which proved to be one of the most efficient ways to train all kinds of Artificial Neural Networks.
In this article, we'll explore how Backpropagation works with Gradient Descent to train Neural Networks. I'll simplify as much as I can and cover how these algorithms work with their code implementation in Python. So, let's get started.
Feed-Forward Neural Network Definition: Forward propagation
Before tackling Backpropagation, we need to understand what is forward propagation and how it works in Feed-Forward Neural Networks. Well, Forward propagation simply refers to the process of passing inputs forward through a neural network to obtain the output.
In the previous article about MLPs, we discussed Neural Networks structure and forward propagation in depth. However, let's do that again in brief.
Here is an animation of a simple Neural Network consisting of 3 layers and 3 neurons undergoing Forward Propagation.
.gif "Forward Propagation Animation") |
| Forward propagation animation |
Let's see what's really happening here, All of the processes within a neural network begin at the input layer. Some initial weights W1 and W2(from the animation) are assigned to the connections between neurons.
The input layer simply passes the given input to the hidden layer of the network, then in the hidden layer, the network finds the weighted sum of inputs(XW) by taking the dot product of the input vectors and the corresponding weight vectors (Note that in the animation, since there are only three neurons and three layers, it can be considered as scalar rather than a vector).
This value is then modified by adding a bias term, followed by applying an activation function. This activation function determines the output of the neuron and passes it on to the next layer.
The equation for the weighted sum of inputs plus a bias by applying an activation function can be given by:
\[output = \Phi (WX + bias) \\ or \\ z = WX + bias \\ output = \Phi (z)\]
Where, W = Weights and X = inputs, Φ = Activation function.
The Backpropagation Algorithm
So you got an idea of what is forward propagation really is, But Forward propagation alone can only be used for getting completely random predictions from a Neural Network. For instance, It's like giving a 7-year-old a math problem to solve without teaching them how to do it. For teaching the kid, we need a good instructor, but for teaching a Neural Network we need a good algorithm, and that is Backpropagation.
Backpropagation is introduced in 1986 in a research paper by three scientists David Rumelhart, Geoffrey Hinton, and Ronald Williams. It was introduced as a great method for training Multi-layer Neural Networks or Multi-Layer Perceptrons. Later, It is adopted as the standard algorithm to train Artificial Neural Networks of all kinds like Convolutional Neural Networks(CNN), Recurrent Neural Networks(RNN), etc since it shows efficiency in the case of Large Neural Networks with thousands or even billions of parameters(weights and biases).
Intuition
So what does basically backpropagation do with Neural Networks? To be really simple, Backpropagation will do just the opposite of Forward Propagation. It propagates the error made by the network during forward propagation back to the network until reaches the input layer.
Forward Propagation = From Input Layer to Output Layer
Backpropagation = From Output Layer to Input Layer
Errors as we know are the incorrect values the network predicts as compared to the labels. During this process of propagating errors backward, the weights assigned to each of the neurons and the biases are also adjusted to reduce this error, and backpropagation is used to find those weights and biases that reduce the error more often and produce an optimal result.
How do Neural Networks learn with Backpropagation?
The main goal of most machine learning algorithms is to learn from training data in order to accurately predict outcomes for new, unseen data.
This process of learning involves finding the optimal set of parameters that allow an algorithm to approximate the given data as closely as possible
Here is a simple animation of how this approximation is done.
 |
| Neural Network Function Approximation |
And Neural Networks are Universal Function Approximators, Which means, they can approximate a wide range of complex functions with a high degree of accuracy, even though the nature of the function is unknown. This is also the reason that Neural Networks are capable of learning really complex patterns.
For a Neural Network to learn the patterns given in the training data, it must tweak the weights given for each neuron to come closer to the patterns in the given data, and backpropagation will help us to do this.
Here is how Backpropagation works step by step:
1. At first, the training data is converted into different mini-batches(parts) and each of these training instances are fed in to the input layer of the Neural Network, then the input layer sends the data into the hidden layer. The algorithm computes the output of all the Neurons in the hidden layer, and this output is passed to the next layer which is the output layer.
2. Next, the algorithm finds the error made by the network by comparing the outputs and the labels. This can be done through a Cost Function, which compares the predicted outputs and actual outputs(labels).
3. Then it computes how much the output layer neurons contributed to the error. This can be done using the Chain Rule in calculus
4. Then it computes how much the previous layer which is the hidden layer contributes to the error made by the output layer, and then this process goes until it reaches the input layer. In each of these backward passes, the algorithm will find the Gradient of the error in each neuron
5. Finally, by using these Gradients, the weights and biases are updated accordingly, and this is done through Gradient Descent Algorithm.
If you don't get this, it's completely ok, next we're going to explain this in detail with the mathematical formula as simply as possible.
Derivation
Now, let's connect the following algorithm we defined as words above with numbers and symbols. The mathematics for backpropagation may seem complex initially, but not that much when we understand the concept.
First, we need to define a cost function for computing the error made by the network. Well, intuitively the error is basically the difference between the predicted output(\(y_{j}\)) and the target output(\(t_{j}\)). So it looks something like this:
\[C:=(t_{j} - y_{j})\]
Summing up all the errors, and avoiding the negative values from the errors the Error (cost function) will look like this:
\[C:=\frac{1}{2}\sum_{j=1}^{J} (t_{j} - y_{j})^{2}\]
To avoid negative numbers for the error, we just squared the error term and for mathematical convenience, we added \(\frac{1}{2}\).

This image represents an extremely simple network that only has two layers and two neurons. The output of activation from the output layer of the network is of course (\(y_{j}\)), let's consider the output of activation in the preceding hidden layer to be \(y_{k}\), and the weight between them is \(\partial w_{kj}\).
Always keep in mind that our goal is to find the weights and biases that minimize the error. In order to achieve this, it is necessary to determine the extent to which changes in the cost are affected by the weights and biases, or how the cost varies with changes in the weights and biases of the network. First let,s consider the case of weights. It can be written like this:
\[\frac{\partial C}{\partial w_{kj}}\]
The symbol \(\partial\) is called Partial and is used when comes to partial derivatives and gradients.
Also, the change in the weights is influenced by the change in the weighted sum of inputs. Let's denote the weighted sum of inputs with the letter \(z_{j}\)
\[z_{j} = \sum w_{kj}y_{k} + b_{k}\]
So the change in weight with respect to the change in the weighted sum of inputs can be given by:
\[\frac{\partial z_{j}}{\partial w_{kj}}\]
So can you tell what is influenced by changes in the weighted sum of inputs? Yes, it's the output of activations(\(y_{j}\)). When the weighted sum of input changes, it also affects the output of activations as well. So it can be represented like this:
\[\frac{\partial y_{j}}{\partial z_{j}}\]
And finally, the change in output of activations \(y_{j}\) also changes(influences) the Error or Cost, it can be represented by:
\[\frac{\partial C}{\partial y_{j}}\]
So we got four partial derivative terms, let's tie them together to see how they are related
When combining the terms we'll get:
\[\frac{\partial C}{\partial w_{kj}} = \frac{\partial z_{j}}{\partial w_{kj}}\frac{\partial y_{j}}{\partial z_{j}}\frac{\partial C}{\partial y_{j}}\]
In this equation, the change in Cost \(\frac{\partial C}{\partial w_{kj}}\) with respect to weights is influenced by three terms, the change in the weighted sum of inputs w.r.t weights \(\frac{\partial z_{j}}{\partial w_{kj}}\), changes in the output of activations w.r.t weighted sum of inputs \(\frac{\partial y_{j}}{\partial z_{j}}\), and the changes in Cost w.r.t output of activations \(\frac{\partial C}{\partial y_{j}}\).
This is what we call the Chain Rule, A fancy fundamental Rule in calculus, that most people find hard, but it's really simple as that.
By using this chain rule, let's find the partial derivatives for each of these terms:
The \(\frac{\partial z_{j}}{\partial w_{kj}}\)(partial derivative) is:
\[\frac{\partial z_{j}}{\partial w_{kj}} = w_{kj}y_{k}+b_{k} = y_{k}\ \ \ \ \ \text{(1)} \]
In order to find the partial derivatives of the output of activations, we need an activation function and its derivative. It doesn't matter which activation function you are choosing, the whole point is to bring non-linearity to our network. However, In this case, I'm considering a sigmoid activation function.
The derivative of the sigmoid function will be:
\[ \begin{align} \dfrac{d}{dx} \sigma(x) &= \dfrac{d}{dx} \left[ \dfrac{1}{1 + e^{-x}} \right] \\ &= \dfrac{d}{dx} \left( 1 + \mathrm{e}^{-x} \right)^{-1} \ \text{[Appying negative exponent]} \\ &= -(1 + e^{-x})^{-2}(-e^{-x}) \ \text{[Applying Reciprocal Rule]} \\ &= \dfrac{e^{-x}}{\left(1 + e^{-x}\right)^2} \\ &= \dfrac{1}{1 + e^{-x}\ } \cdot \dfrac{e^{-x}}{1 + e^{-x}} \ \text{[Expanding the terms]} \\ &= \dfrac{1}{1 + e^{-x}\ } \cdot \dfrac{(1 + e^{-x}) - 1}{1 + e^{-x}} \ \text{[Adding and Subtracting 1]} \\ &= \dfrac{1}{1 + e^{-x}\ } \cdot \left( \dfrac{1 + e^{-x}}{1 + e^{-x}} - \dfrac{1}{1 + e^{-x}} \right) \\ &= \dfrac{1}{1 + e^{-x}\ } \cdot \left( 1 - \dfrac{1}{1 + e^{-x}} \right) \\ &= \sigma(x) \cdot (1 - \sigma(x)) \end{align}\]
And that's the derivative of the sigmoid function. So \(\frac{\partial y_{j}}{\partial z_{j}}\) will be:
\[\frac{\partial y_{j}}{\partial z_{j}} = y_{j}(1-y_{j}) \ \text{considering} \ \sigma (z_{j}) = y_{j}\ \ \ \ \ \text{(2)}\]
Finally, the \(\frac{\partial C}{\partial y_{j}}\):
\[\begin{align} \frac{\partial C}{\partial y_{j}} = \frac{\partial}{\partial y_{j}}(\frac{1}{2}(t_{j} - y_{j})^{2}) \\ &= 2(t_{j}-y_{j})\frac{\partial }{\partial y_{j}}(t_{j}-y_{j}) \ \text{[Applying chain rule]} \\ &= \frac{\partial}{\partial y_{j}}(t_{j}-y_{j}) = -1 \\& = \frac{1}{2}.2(t_{j}-y_{j})(-1) \\ &= -(t_{j}-y_{j}) \end{align}\ \ \ \ \ \text{(3)}\]
Combining Equations 1, 2, and, 3:
\[\frac{\partial C}{\partial w_{kj}} = -(t_{j}-y_{j})y_{j}(1-y_{j})y_{k}\ \ \ \ \ \text{(4)}\]
Now, the changes with respect to biases are not that much complicated. The change in the cost w.r.t bias can be given by:
\[\begin{align} \frac{\partial C}{\partial b_{k}} = \frac{\partial z_{j}}{\partial b_{k}}\frac{\partial y_{j}}{\partial z_{j}}\frac{\partial C}{\partial y_{j}} \\ & \frac{\partial z_{j}}{\partial b_{k}} = \partial(w_{jk}y_{j} + b_{k}) = 1 \\ &= -(t_{j} - y_{j})y_{j}(1 - y_{j}).1 \end{align} \]
So, \(\frac{\partial C}{\partial b_{k}}\) will be:
\[\frac{\partial C}{\partial b_{k}} = -(t_{j} - y_{j})y_{j}(1 - y_{j})\\ \ \ \ \ \text{(5)}\]
Excellent! We have successfully derived the equation for backpropagating the error through a Neural Network. In the equation for weights, (\(y_{k}\)) represents the activation in the previous layer from the current layer of the network. This procedure is repeated recursively until it reaches the input layer, allowing us to determine how much each weight contributes to the overall error of the network.
Well, this equation is just the cost for a single training example, to get the cost or error made by each layer we need to sum up the equation:
For weights:
\[\frac{\partial C}{\partial w_{kj}} = -\sum (t_{j}-y_{j})y_{j}(1-y_{j})y_{k}\]
For biases:
\[\frac{\partial C}{\partial b_{k}} = -\sum(t_{j} - y_{j})y_{j}(1 - y_{j})\]
Let's now compare the algorithm we discussed earlier with the equation we just derived. So far, we have derived the backpropagation algorithm up to step 4. To complete the algorithm, we need to add one more crucial step, which is applying the Gradient Descent algorithm to learn the weights.
The Gradient Descent and Negative Gradient Vector
So, until now we have derived the partial derivative of the cost function w.r.t weights and biases, but in order for Neural Network to adjust the weights and biases, we need to use Gradient Descent. And for that, we need to combine those partial derivatives we found using backpropagation from each layer into a vector known as a Gradient Vector.
\[\nabla C = \begin{bmatrix} \frac{\partial C}{\partial w_{1}} & \\ \frac{\partial C}{\partial b_{1}} & \\ \frac{\partial C}{\partial w_{2}} & \\ \frac{\partial C}{\partial b_{2}} & \\ .& \\ .& \\ .& \\ \frac{\partial C}{\partial w_{k}} & \\ \frac{\partial C}{\partial b_{k}} \end{bmatrix}\]
A Gradient Vector is a special kind of vector that points to the greatest increase of a function. It is a vector that contains the partial derivatives of a function w.r.t its input variables. The magnitude of the vector defines the total rate of change and the direction specifies the greatest increase of a function.
Here is the pictorial representation of a Gradient Vector Field:
 |
| Source: Wikipedia |
As you can see, the arrows represent the Gradient Vector Field, If you match that arrow to the function you can see that those arrows are pointing toward the increase of the function.
.jpg "Backpropagation")
.png)
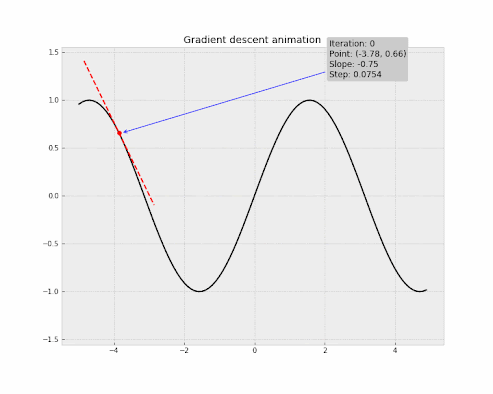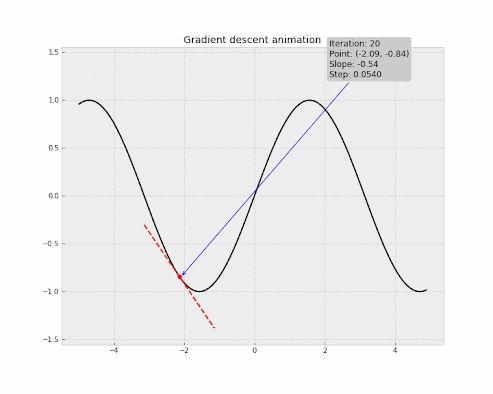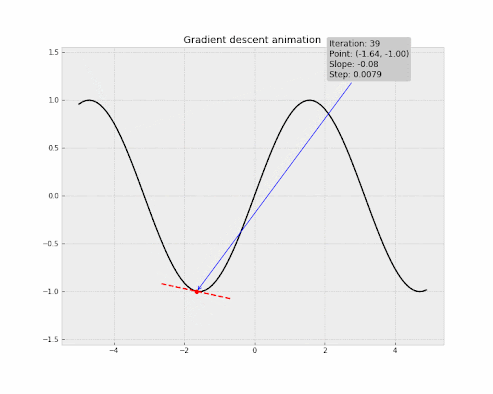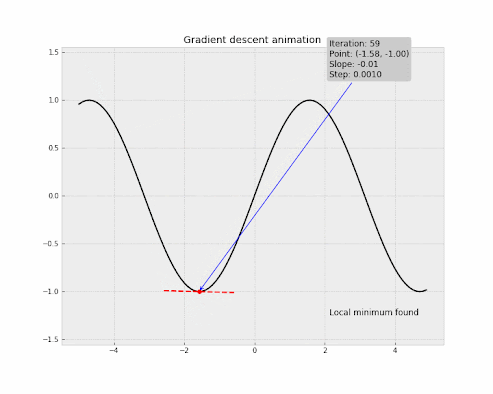
But the main goal of Gradient Descent is to find the steepest descent or the greatest decrease of the cost function rather than the greatest increase. In other words, to reduce the cost of our network, we need to move downwards towards the global minimum, which significantly reduces the cost. To achieve this, we need to take the negative of the Gradient Vector. By doing this, the Gradient Vector points to the direction of the steepest decrease of the cost function.
The Stochastic Gradient Descent is an algorithm with helps find the global minimum of a function. It is used more often in machine learning for training ML models.
Let's take an example to understand Gradient Descent, Imagine you are an adventurer who loves to climb mountains. One day, you climbed a big hill and reached the top, but suddenly the weather changed and it became snowy. You couldn't see the path clearly and you needed to come down the hill as soon as possible without having any trouble in the bad weather.
In this situation, the only way is to take small steps in random directions to see if you are moving downwards. You may not know which direction to take, but you can try taking steps in different directions until you find a path to down.
This is similar to how Gradient Descent works! In machine learning, Gradient Descent is used to find the global minimum of the cost function where the cost is significantly low. For doing this, the algorithm will take small or large steps until it reaches the optimal result. This step is known as the Learning Rate. By taking steps for a certain number of iterations (epochs), the algorithm eventually reaches the global minimum.
Source: Kaggle
Update Rule for Weights and Biases
We're now approaching the final stages of training a neural network. To formulate the update rule for weights and biases we need to combine all the derivations we have done so far into a single rule, which looks kind of like this:
The update rule for weights:
\[\begin{align} \nabla w_{kj} &= w_{kj} - \eta \ \frac{\partial C}{\partial w_{kj}} \\ &=w_{kj}-\eta \ (-(t_{j}-y_{j})y_{j}(1-y_{j})y_{k})[\text{From equation 4}] \end{align} \]
The update rule for biases:
\[\begin{align} \nabla b_{k} &= b_{k} - \eta \ \frac{\partial C}{\partial b_{k}} \\ &=b_{k}-\eta \ (-(t_{j}-y_{j})y_{j}(1-y_{j}))[\text{From equation 5}] \end{align}\]
Where, \(\nabla w_{jk}\) is the new weight
\(\nabla b_{jk}\) is the new bias
\(w_{jk}\) is the previous weight
\(b_{k}\) is the previous bias
\(\eta\) is the learning rate
\(\frac{\partial C}{\partial w_{jk}}\) is the partial derivative of cost with respect to weights.
In terms of matrices we can represent them in the following:
For weights:
\[\scriptsize{\underbrace{\begin{bmatrix} \nabla w_{1,1} & \nabla w_{2,1} & \nabla w_{3,1} & ...\\ \nabla w_{1,2} & \nabla w_{2,2} & \nabla w_{3,2} & ... \\ \nabla w_{1,3} & \nabla w_{2,3} & \nabla w_{k,j} & ... \\ ... & ... & ... & ... \\ \end{bmatrix}}_{\text{New Weight matrix}} = \underbrace{\begin{bmatrix} w_{1,1} & w_{2,1} & w_{3,1} & ...\\ w_{1,2} & w_{2,2} & w_{3,2} & ... \\ w_{1,3} & w_{2,3} & w_{k,j} & ... \\ ... & ... & ... & ... \\ \end{bmatrix}}_{\text{Previous Weight matrix}} - \eta \underbrace{\begin{bmatrix} -(t_{1} - y_{1})y_{1}(1-y_{1}) \\ -(t_{2} - y_{2})y_{2}(1-y_{2}) \\ -(t_{3} - y_{3})y_{3}(1-y_{3}) \\ ....\\ -(t_{j} - y_{j})y_{j}(1-y_{j}) \end{bmatrix}}_{\text{values of the next layer}} \underbrace{\begin{bmatrix} y_{k} & y_{k+1} & y_{k+2} & ... & y_{k+n}\\ \end{bmatrix}}_{\text{values from the previous layer, where k=1}}}\]
For biases:
\[\underbrace{\begin{bmatrix} \nabla b_{1} \\ \nabla b_{2} \\ \nabla b_{3} \\ ... \\ \nabla b_{k} \end{bmatrix}}_{\text{New Bias matrix}} = \underbrace{\begin{bmatrix} b_{1} \\ b_{2} \\ b_{3} \\ ... \\ b_{k} \end{bmatrix}}_{\text{previous biases}}-\eta \underbrace{\begin{bmatrix} -(t_{1} - y_{1})y_{1}(1-y_{1}) \\ -(t_{2} - y_{2})y_{2}(1-y_{2}) \\ -(t_{3} - y_{3})y_{3}(1-y_{3}) \\ ....\\ -(t_{j} - y_{j})y_{j}(1-y_{j}) \end{bmatrix}}_{\text{values of the next layer}}\]
This is how the weights and biases are updated. This process of finding the error, propagating the error backward to find the gradient, and updating the weights using the gradients is done for a specific number of iterations.
.jpg "Backpropagation")
Note: If you are wondering why the weights are represented as a matrix and biases are represented as a vector(ie., a single matrix with one column). It is because each neuron in a given layer has its own set of weights that connect it to the neurons in the previous layer. These weights are typically represented as a matrix. On the other hand, each neuron in a given layer typically has only a single bias term associated with it, which is added to the weighted sum of inputs before the activation function is applied. Because there is only one bias term per neuron, the biases can be represented as a vector (i.e., a single matrix with one column).
.png)
Implementing with Python
So, let's get into the coding part, we are going to implement a simple Neural Network, and train it using Backpropagation and Gradient Descent from scratch only with the help of NumPy.
Let's create a Neural Network class and initialize some instance variables like learning rate, epochs, etc:
The Neural Network class:
import numpy as npclass NN:def __init__(self, input_neurons, hidden_neurons, output_neurons, learning_rate, epochs):# initializing the instance variablesself.input_neurons = input_neuronsself.hidden_neurons = hidden_neuronsself.output_neurons = output_neuronsself.epochs = epochs # Number of iterationsself.lr = learning_rate # Learning rate
This Neural Network only has 3 layers. Now let's assign some random weights and bias
# Links of weights from input layer to hidden layerself.wih = np.random.normal(0.0, pow(self.input_neurons, -0.5), (self.hidden_neurons, self.input_neurons))self.bih = 0# Links of weights from hidden layer to output layerself.who = np.random.normal(0.0, pow(self.hidden_neurons, -0.5), (self.output_neurons, self.hidden_neurons))self.bho = 0
Sigmoid activation function and its derivative:
# Sigmoid Activationdef activation(self, Z):return 1.0/(1.0 + np.exp(-Z))def sigmoid_derivative(self, Z):return self.activation(Z) * (1 - self.activation(Z))
Now let's implement the forward propagation.
def forward(self, input_list):inputs = np.array(input_list, ndmin=2).Thidden_inputs = np.dot(self.wih, inputs) + self.bih # (w.X) + bias (Finding weighted sum of inputs plus bias)hidden_outputs = self.activation(hidden_inputs) # Applying activationfinal_inputs = np.dot(self.who, hidden_outputs) + self.bhofinal_outputs = self.activation(final_inputs)return final_outputs
Everything seems good. We are just finding the weighted sum of inputs plus bias and applying activation in both the inputs and outputs in the hidden and output layers.
Here is the method for backpropagation:
# Back propagationdef backprop(self, inputs_list, targets_list):inputs = np.array(inputs_list, ndmin=2).Ttj = np.array(targets_list, ndmin=2).T # Targets# passing inputs to the hidden layerhidden_inputs = np.dot(self.wih, inputs) + self.bih# Getting outputs from the hidden layerhidden_outputs = self.activation(hidden_inputs)# Passing inputs from the hidden layer to the output layerfinal_inputs = np.dot(self.who, hidden_outputs) + self.bho# Getting output from the output layeryj = self.activation(final_inputs)# Finding the errors from the output layeroutput_errors = -(tj - yj)# Finding the error in the hidden layerhidden_errors = np.dot(self.who.T, output_errors)# Updating the weights using Update Ruleself.who -= self.lr * np.dot((output_errors * self.sigmoid_derivative(yj)), np.transpose(hidden_outputs))self.wih -= self.lr * np.dot((hidden_errors * self.sigmoid_derivative(hidden_outputs)), np.transpose(inputs))#updating biasself.bho -= self.lr * (output_errors * self.sigmoid_derivative(yj))self.bih -= self.lr * (hidden_errors * self.sigmoid_derivative(hidden_outputs))pass
Nothing too complicated. Just python implementation of mathematical concepts we derived earlier. However, if you have any confusion, look again back to the formulas.
Now let's tie the backpropagation and gradient descent together using the fit method which is described here:
# Performing Gradient Descent Optimization using Backpropagationdef fit(self, inputs_list, targets_list):for epoch in range(self.epochs):self.backprop(inputs_list, targets_list)print(f"Epoch {epoch}/{self.epochs} completed.")
To predict using the newly updated weights and biases, we can define a predict method:
def predict(self, X):outputs = self.forward(X).Treturn outputs
Training the network
data = np.array([[0, 0, 1, 0, 1],[1, 1, 1, 0, 0],[1, 0, 1, 1, 1],[0, 1, 1, 1, 0],[1, 0, 0, 1, 1],[0, 1, 0, 0, 1],[1, 1, 0, 1, 0],[0, 0, 0, 1, 0],[1, 0, 0, 0, 1],[0, 1, 1, 0, 1]])target = np.array([[0],[1],[1],[0],[1],[0],[1],[0],[1],[1]])nn = NN(data.shape[1], 10, 1, 0.1, 1000)nn.fit(data, target)nn.predict(data)output:array([[0.00902083],[0.99684914],[0.99625946],[0.00701471],[0.99640161],[0.00922074],[0.99667569],[0.00483531],[0.99673216],[0.98974989]])
And we have done it! The outputs are great, the model predicted the probabilities which are close to the target values.
Here is the full version of the code:
import numpy as npclass NN:def __init__(self, input_neurons, hidden_neurons, output_neurons, learning_rate, epochs):# initializing the instance variablesself.input_neurons = input_neuronsself.hidden_neurons = hidden_neuronsself.output_neurons = output_neuronsself.epochs = epochs# Links of weights from input layer to hidden layerself.wih = np.random.normal(0.0, pow(self.input_neurons, -0.5), (self.hidden_neurons, self.input_neurons))self.bih = 0# Links of weights from hidden layer to output layerself.who = np.random.normal(0.0, pow(self.hidden_neurons, -0.5), (self.output_neurons, self.hidden_neurons))self.bho = 0self.lr = learning_rate # Learning rate# Sigmoid Activationdef activation(self, Z):return 1.0/(1.0 + np.exp(-Z))def sigmoid_derivative(self, Z):return self.activation(Z) * (1 - self.activation(Z))# Forward propagationdef forward(self, input_list):inputs = np.array(input_list, ndmin=2).Thidden_inputs = np.dot(self.wih, inputs) + self.bih # (w.X) + bias Finding dot producthidden_outputs = self.activation(hidden_inputs) # Applying activationfinal_inputs = np.dot(self.who, hidden_outputs) + self.bhofinal_outputs = self.activation(final_inputs)return final_outputs# Back propagationdef backprop(self, inputs_list, targets_list):inputs = np.array(inputs_list, ndmin=2).Ttj = np.array(targets_list, ndmin=2).T # Targets# passing inputs to the hidden layerhidden_inputs = np.dot(self.wih, inputs) + self.bih# Getting outputs from the hidden layerhidden_outputs = self.activation(hidden_inputs)# Passing inputs from the hidden layer to the output layerfinal_inputs = np.dot(self.who, hidden_outputs) + self.bho# Getting output from the output layeryj = self.activation(final_inputs)# Finding the errors from the output layeroutput_errors = -(tj - yj)# Finding the error in the hidden layerhidden_errors = np.dot(self.who.T, output_errors)# Updating the weights using Update Ruleself.who -= self.lr * np.dot((output_errors * self.sigmoid_derivative(yj)), np.transpose(hidden_outputs))self.wih -= self.lr * np.dot((hidden_errors * self.sigmoid_derivative(hidden_outputs)), np.transpose(inputs))#updating biasself.bho -= self.lr * (output_errors * self.sigmoid_derivative(yj))self.bih -= self.lr * (hidden_errors * self.sigmoid_derivative(hidden_outputs))pass# Performing Gradient Descent Optimization using Backpropagationdef fit(self, inputs_list, targets_list):for epoch in range(self.epochs):self.backprop(inputs_list, targets_list)print(f"Epoch {epoch}/{self.epochs} completed.")def predict(self, X):outputs = self.forward(X).Treturn outputs
Conclusion:
In conclusion, backpropagation and gradient descent are two important techniques used in the training of neural networks, but they serve different purposes. Backpropagation is used to calculate the gradients of the loss function with respect to the weights of the network, while gradient descent is an optimization algorithm that uses these gradients to update the weights in the direction of the steepest descent. By understanding the intuition, mathematical derivation, and implementation of backpropagation and gradient descent, we have gained a deeper understanding of the inner workings of neural network training. These techniques play a fundamental role in the optimization process and form the backbone of many modern deep-learning algorithms. Therefore, a clear understanding of backpropagation and gradient descent is crucial for anyone looking to develop deep-learning models and stay up-to-date with the latest advances in the field.
Thanks for reading!