

Introduction
This article presents the steps of a quick tutorial on how to scrape jobs from Indeed. Using python, bs4, selenium, and pandas, we'll be able to extract information from indeed.com and construct a pandas data frame. Before we begin, let's understand web scraping simply.
Imagine if you are trying to get much information about something from various web pages and articles that need to be stored in a suitable format, for instance, an excel file. One way is to go through all those websites and write the useful information to the excel sheets manually. But programmers tend to do it in an easy way which is web scraping. Web scraping is the technique of extracting a large amount of data from different web pages that can be stored in a suitable format.
Scraping job details from Indeed
Indeed is one of the largest American job listing portals which consists of millions of job listings all over the world from different small scale and large scale companies including startups. Scraping job details from indeed really helps you to get a large amount of information about different jobs, locations, actively hiring companies, ratings, etc.
Here are the steps involved
1. Install and import necessary modules
2. Send some basic queries like job title or company name and location to the Indeed website using selenium

3. Fetch the current URL after sending the queries to the website using selenium.
4. Parse the page using requests and Beautiful Soup
5. Fetch the information about job title, company name, rating, location, simple description, date of posting, etc

Installing and importing libraries
First of all, we need to install some specific modules including a chrome driver for selenium. You can find the versions of chrome driver for different OS from This link. Check the version of chrome for installing the correct version of the chrome driver.
After installing the chrome driver move it to the working directory.
Now we can install the libraries using 'pip'
$ pip install requests selenium bs4 pandas lxml
After installation, import the modules
import requestsfrom bs4 import BeautifulSoupimport pandas as pdfrom selenium import webdriverimport timefrom selenium.webdriver.common.keys import KeysHEADERS ={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0", "Accept-Encoding":"gzip, deflate", "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "DNT":"1","Connection":"close", "Upgrade-Insecure-Requests":"1"}
Here requests help to send an HTTP request using python, Selenium is an automation tool that helps here to send queries to the website, lxml can convert the page into XML or HTML format. bs4 module for parsing the web page and pandas to convert the data into a CSV file.
We are using a User-Agent header string for servers to identify the application, OS, version, etc.
Sending job title and location using selenium
Now let's create a function that sends queries to the web page and returns the current URL:
def get_current_url(url, job_title, location):driver = webdriver.Chrome()driver.get(url)time.sleep(3)driver.find_element_by_xpath('//*[@id="text-input-what"]').send_keys(job_title)time.sleep(3)driver.find_element_by_xpath('//*[@id="text-input-where"]').send_keys(location)time.sleep(3)driver.find_element_by_xpath('/html/body/div').click()time.sleep(3)try:driver.find_element_by_xpath('//*[@id="jobsearch"]/button').click()except:driver.find_element_by_xpath('//*[@id="whatWhereFormId"]/div[3]/button').click()current_url = driver.current_urlreturn current_urlcurrent_url = get_current_url('https://in.indeed.com/','Data Scientist',"Bengaluru")print(current_url)Output:'https://in.indeed.com/jobs?q=Data%20Scientist&l=Bengaluru%2C%20Karnataka&vjk=d9e0ee7cc8b5e5b4'
This function opens indeed.com using the specified URL as one of its parameters. Then it sends the job title or company name and location to the site using selenium. After that, we'll get a new page and its URL which consists of all the job details related to the job title and location you have specified as its parameters. Lastly, it returns the current URL which consists of jobs and their details so that we can simply scrape it using Beautiful Soup.
Copying Xpath:

Scraping jobs using Beautiful Soup
Now let's get into the scraping part. Let us define another function that will do the scraping stuff for us. This function will retrieve data like the job title, company name, job rating, location, date of posting, and simple description.
def scrape_job_details(url):resp = requests.get(url, headers=HEADERS)content = BeautifulSoup(resp.content, 'lxml')jobs_list = []for post in content.select('.job_seen_beacon'):try:data = {"job_title":post.select('.jobTitle')[0].get_text().strip(),"company":post.select('.companyName')[0].get_text().strip(),"rating":post.select('.ratingNumber')[0].get_text().strip(),"location":post.select('.companyLocation')[0].get_text().strip(),"date":post.select('.date')[0].get_text().strip(),"job_desc":post.select('.job-snippet')[0].get_text().strip()}except IndexError:continuejobs_list.append(data)dataframe = pd.DataFrame(jobs_list)return dataframescrape_job_details(current_url)
The request.get()(2nd line) function returns the data of the entire webpage. Then, we need to convert the received data into HTML form using Beautiful Soup and lxml. The next step is to find the CSS selectors and retrieve the raw text inside the tags that contain these CSS selectors. The CSS selectors given in the code are probably the same on the web page but sometimes it may change.

By looping through all the job posts we'll get much information about it. Lastly, we converted the data into a pandas data frame and simply returned it.
The output will look like this:
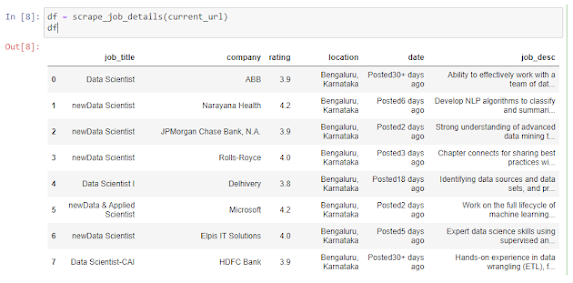
You'll get the details about the job title, company name, rating, location, date of posting, and a simple job description. You can save it as a CSV file using df.to_csv("jobs.csv").
You might also like: Scrape the bestselling products on Amazon using Python and Beautiful Soup